Парсер фрилансеров
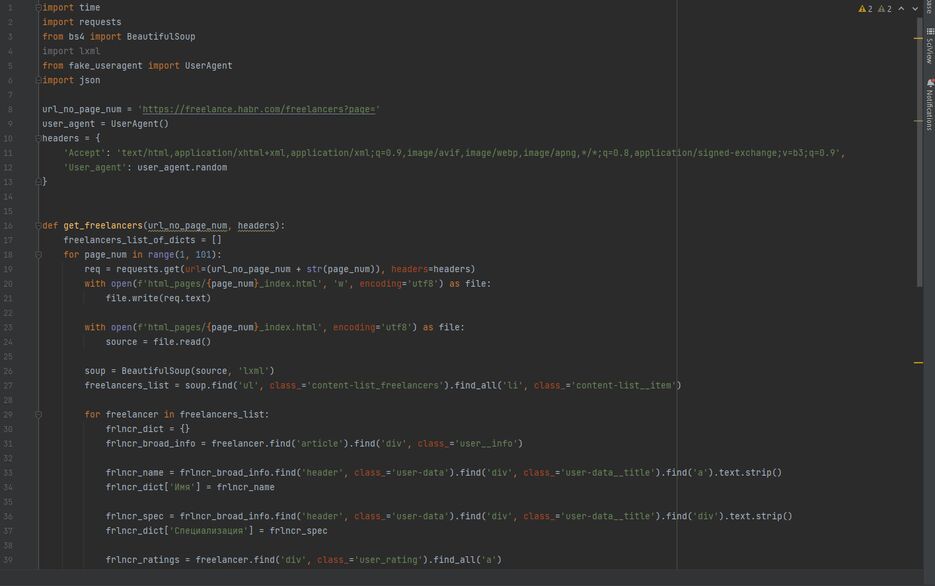
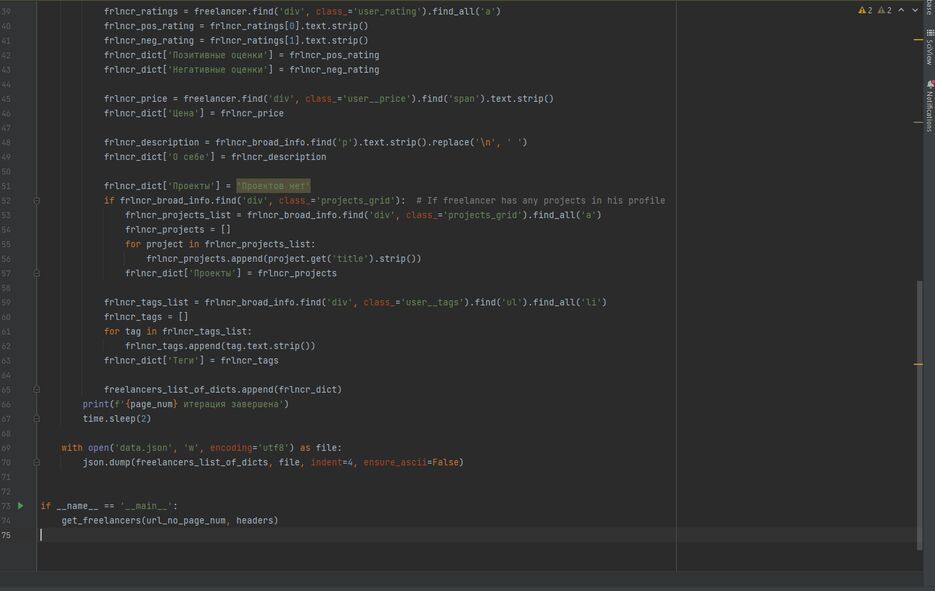

Использованные библиотеки: requests, json, time, beautifulsoup4, lxml, fake_useragent.
Не уверен, можно ли писать название биржи, с которой я парсил, поэтому скажу лишь, что это не Веблансер.
Парсер работает только на первых ста страницах списка специалистов, потому что парсить их все (>4700) было бы слишком долго и бессмысленно для неоплачиваемого проекта. Хотя, если кому-то вдруг очень нужно, то можно спарсить абсолютно всех фрилансеров
Чтобы не долбить сайт запросами сверх меры, я одним реквестом записывал каждую страницу в html-файл, а потом уже работал с этой загруженной копией. Ещё, чтобы парсер выглядел человечнее, он рандомно генерирует себе User_agent каждую итерацию, а между самими итерациями есть пауза в 2 секунды.
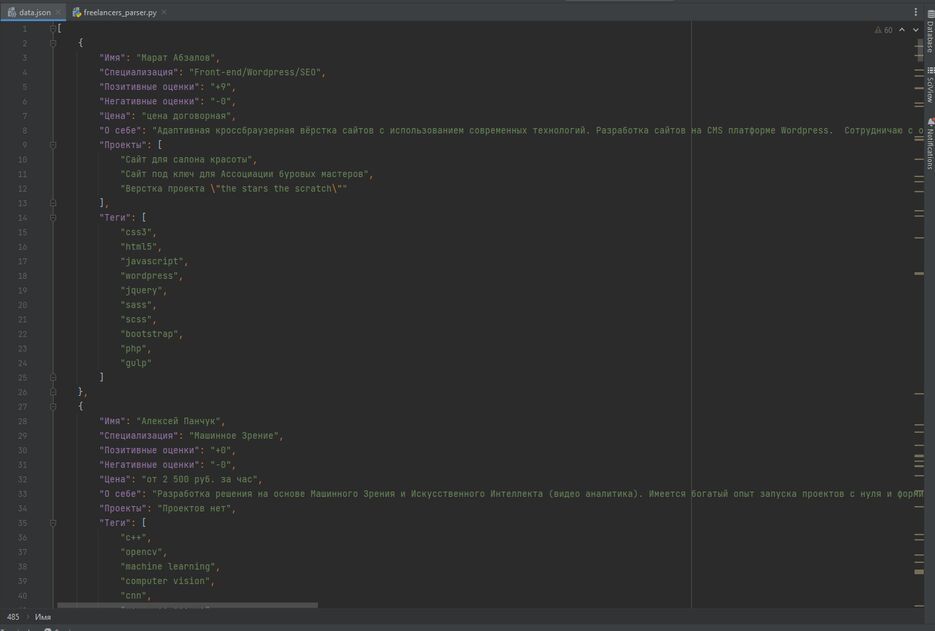
У каждого фрилансера я нашёл:
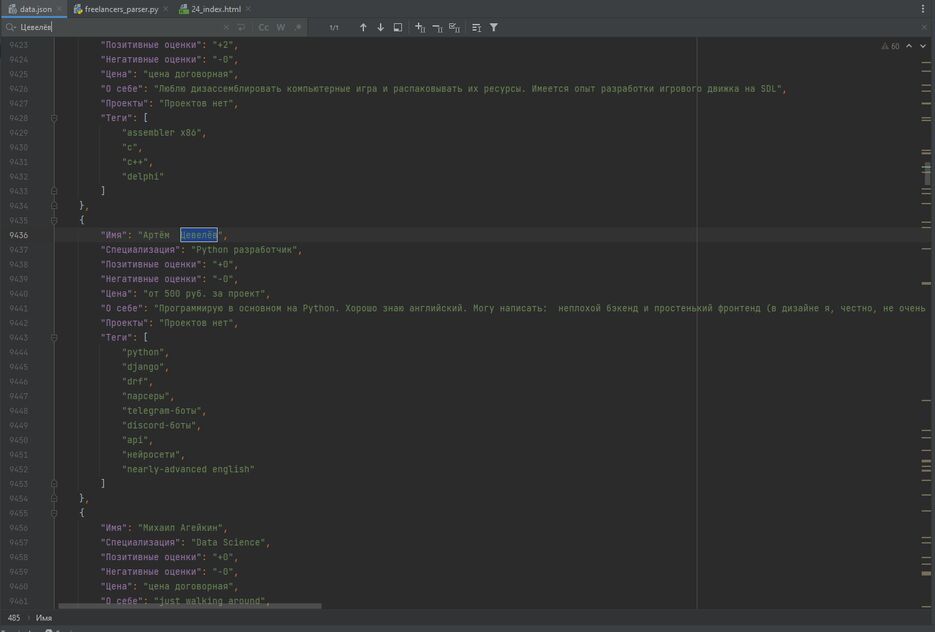
[list][*]Имя[*]Специализацию[*]Позитивные оценки[*]Негативные оценки[*]Цену работы[*]Текст о себе[*]Проекты в портфолио (или их отсутствие)[*]Указанные теги[/list]Затем всё это я залил в json-файл, который длиной вышел в 46 тысяч строк. [i](сам я, кстати, нахожусь на строчках 9436-9454)[/i]
HTML